
Il y a quelques mois en arrière, j’ai déployé ma première fonction Lambda AWS pour le compte de mon client. 🥳
Le but était de mettre en place une Lambda qui détecte la création de loggroups puis, de vérifier qu’ils aient bien une rétention de deux semaines. Si ce n’était pas le cas, la fonction rectifiait le tir en mettant en place la rétention attendue. Je ne rentrerai pas plus dans le détail, ce n’est pas le but de l’article.
Pour cela, je me suis attelé à l’écriture du code en python. Je fais quelques tests et je valide le bon fonctionnement ! 🥳
Plusieurs semaines passent, un collègue me fait remarquer qu’il y a énormément d’invocations de ma lambda dans les logs CloudTrail. 🥵
Je vais de ce pas voir ce qu’il se passe. En effet, je constate un nombre d’invocations faramineux. La lambda se déclenchait en boucle, essayant de mettre une rétention de 2 semaines sur un loggroup qui n’existait plus… Inutile de vous préciser que la facture AWS à… Un petit peu grimper. 💸 💸 💸
Je me suis rendu compte, que les lambdas étaient un peu plus complexe que juste « oh, c’est du serverless, je ne m’occupe de rien, je push mon code. ».
J’ai eu envie de comprendre (heureusement pour le client 😅) comment fonctionne en détail le scaling des Lambdas.
Vous aussi ? Parfait, alors zepartiiiii 😁😁
Mais dis moi Antoine, une Lambda, c’est quoi ?
AWS Lambda est un service de calcul serverless (sans serveur) qui peut être mis à l’échelle, d’une seule requête à des centaines de milliers par seconde (tient, ça me rappelle quelque chose 😅).
Nous déployons notre code dans le cloud et AWS s’occupe du reste. Soit, de l’infrastructure et de sa mise à l’échelle.
Vous l’aurez compris, serverless ne veut pas dire qu’il n’y pas de serveurs (🤯). Derrière, AWS gère toute une ferme de machines qui font tourner nos Lambdas.
Quand nous écrivons notre code pour une fonction, il y a deux composants auxquels il faut penser : la concurrence et les requêtes par seconde. Je vais détailler ces points dans la suite de l’article.
Sachez que le modèle de payement est dit “pay as you go”, en bon français, “payer ce que vous utilisez”. Ce qui va nous être facturé sera uniquement le temps de calcul et les temps d’invocation de notre Lambda. Ceci explique ma facture 😅
Ce mode de paiement est assez commun lorsque l’on parle de Cloud. Cependant, il faut porter une attention particulière afin de ne pas sur-utiliser nos ressources.
Comment sont invoquées nos Lambda ?
Une fonction Lambda peut être exécutée de deux manières.
La première est le modèle synchrone, c’est-à-dire que l’on va “attendre” pendant l’exécution de la fonction, avant de recevoir une réponse.
Par exemple, vous interrogez une API pour avoir une liste d’utilisateurs. Vous allez devoir attendre l’exécution de la fonction pour qu’elle vous retourne la liste de vos utilisateurs.
La seconde, est le modèle asynchrone. On va se baser sur les événements. La fonction lambda place en file d’attente l’événement à traiter et renvoie une réponse immédiatement.
L’environnement d’exécution d’une fonction Lambda
Nous avons deux processus de démarrage :
- Un démarrage à froid
- Un démarrage à chaud
Pour faire très simple, lors de la première invocation, on va toujours procéder par un démarrage à froid. AWS va procéder aux étapes d’initialisation, permettant de préparer la phase d’invocation :

Une fois ces étapes faites, lorsque nous allons invoquer une nouvelle fois la fonction, ce sera avec un démarrage à chaud. Autrement dit, notre code au sein de la fonction va s’exécuter avec la phase d’invocation directement.

Lorsqu’une requête arrive pour la première fois sur une fonction Lambda, une phase d’initialisation commence. Durant cette phase, la Lambda ne peut traiter qu’une seule requête à la fois.
Cependant, il est tout à fait possible d’avoir plusieurs phases d’initialisation en simultanée.
On dit q’une requête est terminée à la fin de la phase d’initialisation et d’invocation. On peut alors traiter une nouvelle requête. Mais cette fois-ci avec un démarrage à chaud.
Il paraît qu’une image vaut mille mots, alors je vous ai fait un petit schéma récapitulatif :
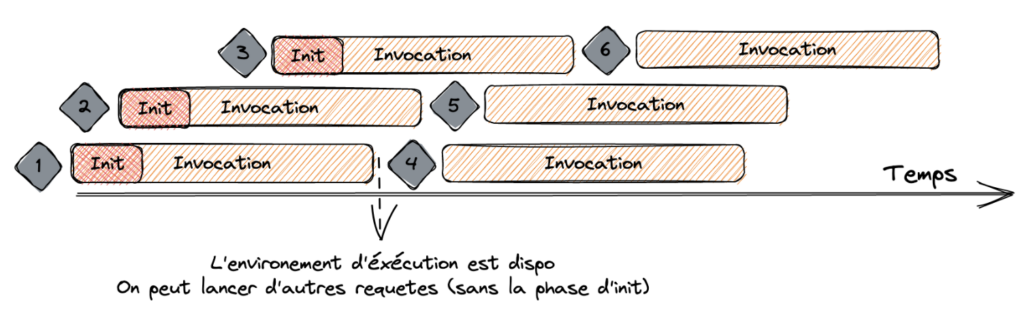
Une fois la requête 1 terminée, l’environnement d’exécution est disponible pour traiter une autre requête. Lorsque la requête 4 arrive, Lambda réutilise l’environnement d’exécution de la requête 1 et exécute l’invocation suivante, et ainsi de suite avec les requêtes 5 et 6.
Comprendre le principe de concurrence
La notion de transaction par seconde est la somme de toutes les invocations à un instant T. Si une fonction prend 1 seconde à s’exécuter et qu’il y a 3 autres invocations qui arrivent en même temps, Lambda va créer 4 environnements d’exécution.
Dans ce cas de figure, Lambda va exécuter 4 requêtes par seconde. Une nouvelle fois, voici un schéma représentant ce principe :
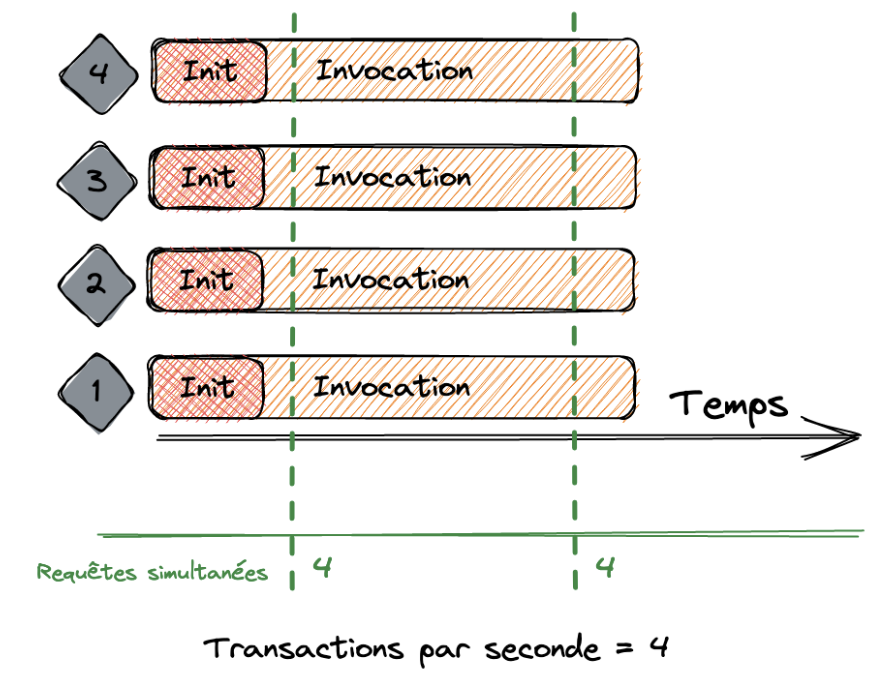
Dans le schéma ci-dessus, nous nous retrouvons dans le cas de figure où la concurrence et les transactions par seconde sont identiques.
Cependant, ce n’est pas toujours le cas. Imaginons que notre Lambda à un temps d’exécution de 500 millisecondes. Nous aurons toujours une concurrence de 4, mais les transactions par seconde seront au nombre de 8. Un petit schéma ? 👇
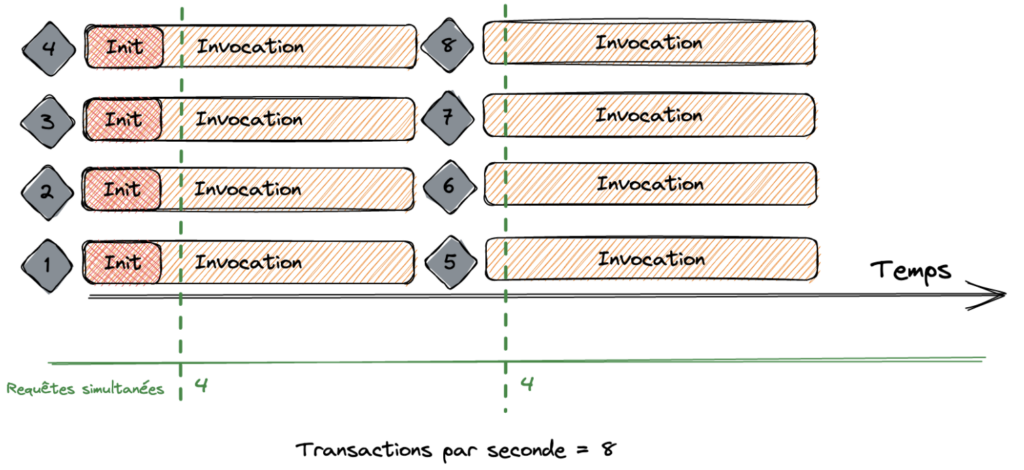
Sur le schéma, on constate que l’on a 4 invocations et 4 requêtes simultanées. Elles s’exécutent en une demie seconde, nous pouvons dans ce cas, utiliser les démarrages à chaud sur une même période de temps. Nous avons donc 8 transactions par seconde.
Il est possible de voir la concurrence de vos Lambda avec CloudWatch metrics. En utilisant la métrique ConcurrentExecutions.
Le principe de concurrence réservée
Avec ce que l’on a vu précédemment et l’introduction de cet article, vous imaginez bien que si l’on ne fait pas attention, on peut invoquer notre Lambda un peu (beaucoup) trop souvent 😅.
C’est pourquoi il existe un paramètre de concurrence réservée qui nous permet d’appliquer une limite à ne pas dépasser. En cela, nous sommes en mesure de contrôler la mise à l’échelle de notre fonction jusqu’à la valeur de la concurrence réservée.
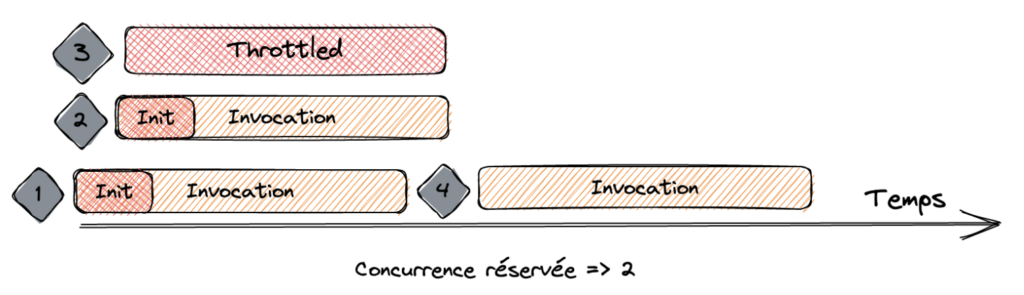
Je ne peux que vous conseiller de mettre en place cette protection et d’éviter des centaines et des centaines d’invocations concurrentes non souhaitées (votre service financier vous remerciera 🤑🤑).
Je vais introduire trèèèès brièvement le principe de concurrence provisionnée. Cette dernière permet de paramétrer un nombre minimum d’environnements d’exécution prêt à l’emploi, réduisant l’impact du démarrage à froid. Votre fonction sera prête à être invoquée directement.
Ce principe peut vous intéresser lors de requêtes synchrones ou lors d’un pic de trafic attendu.
Les quotas
Nous avons vu qu’une fonction Lambda pouvait scale très facilement et très rapidement.
Parlons à présent des quotas. 🙂
Nous avons le Burst concurrency quota, qui permet de lancer jusqu’à 3 000 Lambdas concurrentes par minutes, dans les grandes régions (Oregon, Virginia, Ireland).
Pour les autres régions, le quota est entre 1000 (Tokyo, Frankfurt, Ohio) et 500 pour toutes les autres.
À noter que c’est une hard limit, il n’y a pas de moyen d’augmenter ce quota et il est partagé pour toutes les fonctions d’un compte.
Le deuxième type de quota est le Account concurrency quota. C’est le nombre concurrence par défaut d’une région sur un compte AWS. Il est de 1000 et il est partagé pour toutes les Lambdas du compte, mais celui-ci peut être augmenté.
Conclusion
On arrive à la fin de cet article.
On peut mettre en lumière plusieurs points.
Le premier, c’est que les services managés ou serverless ne sont pas si simples. Ok, on s’abstrait du côté infrastructure, mais nous ne sommes pas exempts de coûts.
Le deuxième et dernier point que je souhaite aborder, c’est qu’il nous arrive parfois de faire des erreurs liées à une méconnaissance sur un sujet, une techno.
Ce n’est pas grave. La preuve, cela m’a donné envie de creuser ce sujet, permit d’apprendre et de comprendre comment fonctionne le scaling des lambdas. Et en plus, j’ai le luxe de pouvoir vous partager tout ça ! Génial non ? 😁
Cela ne serait certainement jamais arrivé sans ma petite boulette. 😅
Comments are closed.